




コーセーは、慶應義塾大学 青木義満教授との共同研究により、リップメイクの形状や色の類似性に基づいて、主観的なバイアスなく画像を自動分類することを可能とする「教師なし距離学習モデル」を開発した。同モデルは人手によるラベル付けを必要としないため効率的で、SNSなどにおけるリップメイクのトレンド分析への応用が期待できる。その高い分類精度から、少数派のスタイルを取りこぼしづらい点も特長だ。同研究成果の一部は2025年9月15~18日にフランス・カンヌで開催の第35回IFSCC学術大会にて発表した。
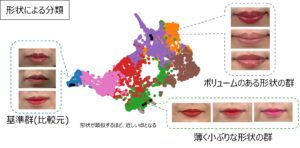

図1:「教師なし距離学習モデル」によるリップメイクの分類への応用例
近年、メイクアップは美しさの追求のみならず、社会のトレンドや自分らしさの表すものとなっている。SNSでは日々さまざまな画像が投稿され、そのトレンドの移り変わりも非常に速くなっている。このように多様で動的なメイクアップのトレンドを捉えるためには、膨大なデータを処理し、細かな差異を解析できる自動分類モデルの活用が有効だ。しかし、従来のモデルでは人間が画像に加えるラベル(画像に対する意図的なタグ付け)が必要であり、手間やコストがかかるのに加えて、主観や文化的な偏りが入り込みやすく、少数派が過小評価されるリスクがあった。そこで同研究では、ラベル付けを必要とせず、純粋に画像間の類似性を学習できる「教師なし距離学習モデル」の開発に取り組んだ。
今回の「教師なし距離学習モデル」の開発では、“Makeup transfer”と呼ばれる画像生成系の技術を用いて、画像を整理するための深層学習を設計している。この技術によって二つの画像から生成される画像を擬似的な類似ペアと非類似ペアとすることで、人手によるラベル付けをすることなく、リップメイクの形状と色を明確に分離して学習させることができる(図2)。この仕組みにより、大きさやRGB値といった一般的な指標では表しにくい“雰囲気レベルの距離の近さ=意味的な類似性”を、形状と色の二つの特徴として落とし込み、教師なし(ラベル付けなし)で画像間の距離を学習できるようになった。その結果、リップメイク間の微細で複雑な違いを定量的に表現し、形状と色によって自動分類することが可能となった(図1)。
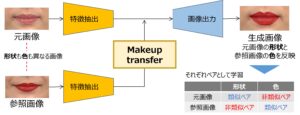
図2:「教師なし距離学習モデル」における学習の概念図
開発した「教師なし距離学習モデル」の精度を、公開されている大規模な画像データセットを用いて検証したところ、従来の教師なし学習モデルを上回る精度を示し、精度が高い傾向がある教師あり学習モデルと比較しても遜色のない性能を確認した。特徴的なのは少数派の分類であり、データ全体のわずか1%しか存在しないスタイルにおいても、従来手法を大きく上回る精度を達成した。これにより、「教師なし距離学習モデル」は少数派を取りこぼさず、多様なリップメイクを的確に分類できる手法であることが分かった。
今回開発した「教師なし距離学習モデル」は、ラベルに依存することなく、公平で、効率的なリップメイクの分類を可能とする手法である。これは流動性の高いSNSにおける少数派を含んだトレンド分析や、お客一人一人の美容スタイルを見つけ出すことへの応用が期待できる。同社は今後も、他のメイク分類への応用など、より多くの人が自分らしい美容を楽しめるような研究開発を推進していくとしている。
月刊『国際商業』2025年12月号掲載

























